Hello world for Machine Learning
Machine learning is growing structurally and expanding to several industries all over the globe. It’s the most sought-after technology in today's market.
Machine learning has been embraced as the best approach to build smart applications, as well as to solve virtually unsolvable problems. Also known as predictive analytics, it is mainly the mathematical method that "learns" from previous sets of data which inputs in the system allowing it to produce desirable outputs. It has two approaches: inductive and deductive. Inductive Machine learning generalises observations. Deductive Machine learning can be characterised as a search for patterns within a set of data. ML algorithms have been getting smarter since their invention. Big Data is constantly growing, and it's changing how we develop products.
The rationale for this is the massive amount of data produced by applications, the increase of computation power over the last few years, and better algorithms development. The technology plays a crucial role in multiple critical applications, notably data mining, natural language processing, image recognition, automation, and expert systems. The potential opportunities for Machine learning are so numerous that it is hard to list them all.
ML allows the system to learn automatically and predict without human intervention. The hello world program elaborated in this article will enable you to understand the concept, the built environment, and how coding works for ML algorithms. A few lines of Python is all it takes to write the first ML program. To do that, we'll work with an open-source library: scikit-learn.
Machine Learning and its importance
ML is a subfield of Artificial Intelligence (AI). Early AI programs typically excelled at just one given thing. Today we want to write one program that can solve several problems without any rewrites. Alpha Go is a valid example where similar software can also learn to play Atari games. ML makes that possible. It's the study of algorithms that learn from examples and experience instead of relying on hard-coded rules.
In ML, instead of defining the rules and expressing them in a programming language, answers (typically called labels) are provided with the data. The machine will infer the rules that determine the relationship between the labels and the data. The data and labels are used to create ML Algorithms, typically called models. Using this model, when the machine gets new data, it predicts or correctly labels them.

Figure 1: Machine Learning programming
For example, if we train the model to discern between apples and oranges, the model can predict whether it is an apple or an orange when new data is presented. The problem sounds easy, but it is impossible to solve without ML. You'd need to write tons of rules to tell the difference between apples and oranges. With a new problem, you need to restart the process. There are many aspects of the fruit that we can collect data on, including colour, weight, texture, and shape. For our purposes, we'll pick only two simple ones as data: weight and texture. In this article, we will explain how to create a simple ML algorithm that discerns between an apple and an orange.
Creating your first Machine Learning model
To discern between an apple and an orange, we create an algorithm that can figure out the rules so we don't have to write them by hand. And for that, we're going to train what's called a classifier. You can think of a classifier as a function. It takes some data as input and assigns a label to it as output. The technique of automatically writing the classifier is called supervised learning.
Supervised learning
To use supervised learning, we follow a simple procedure with a few standard steps. The first step is to collect training data. These are essentially examples of the problem we want to solve. Step two is to use these examples to train a classifier. Once we have a trained classifier, the next step is to make predictions and classify a new fruit.

Figure 2: Machine Learning procedure
Setting up the environment
To code this program, we will work with scikit-learn, a free ML library for Python. There are many ways to download scitkit-learn, but the easiest method is to use Anaconda. You will get all the dependencies set up, and it works well in Windows, Mac, or Linux.
Figure 3: Anaconda Installation & Anaconda Prompt
Anaconda is an open-source distribution for Python and R. It is used for data science, ML, deep learning, etc. With the availability of more than 300 libraries for data science, it becomes relatively optimal for any programmer to work on Anaconda. Install Anaconda as per your machine's OS and system requirements. After you finish the installation, open the Anaconda prompt, and type Jupyter notebook. You are now all set up to run "The Hello World Program" for ML. We will now discuss the individual steps.
1. Collect training data
To collect training data, assume we head out to an orchard and collect some data. We look at different apples and oranges and write down their descriptive measurements in a table. In ML, these measurements are called features. To keep things simple, we've used only two types of data – how much each fruit weighs in grams and its texture, which can be bumpy or smooth.
Each row in our training data depicts an example. It describes one piece of fruit. The last column is known as the label. It identifies what type of fruit is in each row, and in this case, there are only two possibilities – apples or oranges. The more training data you have, the better a classifier you create.
| Weight | Texture | Label |
|---|---|---|
| 155 | rough | Orange |
| 180 | rough | Orange |
| 135 | smooth | Apple |
| 110 | smooth | Apple |
2. Training the classifier
With the dataset prepared, the next step is to set up our training data and code it. For this, open a new Python 3 notebook from the Jupyter Notebook web browser and start coding.


Figure 4: Jupyter Notebook environment
Before we set up our training data, ensure the scikit-learn package is loaded. Scikit-learn provides a range of supervised and unsupervised learning algorithms via a consistent interface in Python.
import sklearn
Now let's write down our training data in code. We will use two variables – features and labels.
features = [[155, “rough”], [180, “rough”],[135, “smooth”],[110, “smooth”]]
labels = ["orange", "orange", "apple", "apple"]
In the preceding code, the features contain the first two columns, and labels contain the last. Since scikit-learn works best with integers, we're going to change the variable types of all features to integers instead of strings – using 0 for rough and 1 for smooth. We will do the same for our labels – using 0 for apple and 1 for orange.

The next step involves using these example features to train a classifier. The type of classifier we will use is called a decision tree. There are many different classifiers, but for simplicity, you think of a classifier as a box of rules. Before we use our classifier, we must import the decision tree into the environment.
from sklearn import tree
Then on the next line in our script, we will create the classifier.
clf = tree.DecisionTreeClassifier()
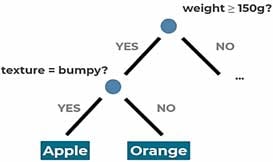
Figure 5: Decision Tree classifier
At this point, the classifier is just an empty box of rules since it continues to be unaware of apples or oranges. To train it, we'll need a learning algorithm. If you think of a classifier is a box of rules, you can think of a learning algorithm as the procedure that creates them. It does so by finding patterns in the training data.
For example, it might notice oranges tend to weigh more, so it will create a rule saying that the heavier the fruit is, the more likely it is to be an orange. In scikit, the training algorithm is included in the classifier object, and it's called fit. You can think of fit as being a synonym for "find patterns in data."
clf = clf.fit(features, labels)

3. Make predictions
We have a trained classifier. Let's test it and use it to classify a new fruit. The input to the classifier is the feature for a new example. Let's say the fruit we want to classify is 150 grams and bumpy. Let's see if our ML algorithm can make such a prediction:
print (clf.predict(X = [[150, 0]]))

It works! The output is what we expected: 1 (orange).
If everything worked for you, then congratulations! You have completed your first ML project in Python. You can create a new classifier for a new problem just by changing the training data. Fortunately, with the abundance of open source libraries and resources available today, programming with ML has become more comfortable and accessible to a rising number of users every day.
Once you have a basic understanding of ML software programs and algorithms, you can scale your project using AI-based development boards. Decide on a hardware platform based on your application, and you are ready to go for real-world deployment. Here are a few examples of AI platforms to help you to get started:
Ultra96V2: Avnet’s Ultra96 is an easy-to-use platform based on the integrated Dual-core Arm Cortex-R5F real-time, multiprocessing system with programmable logic Xilinx Zynq UltraScale+ MPSoC. The use of programmable logic accomplishes the fine balance between performance and power. The tight coupling of the processing system (PS) and programmable logic (PL) in the Zynq MPSoC allows accelerating the ML algorithm and function in a more responsive, deterministic, and power-efficient way than traditional CPU or GPU-based machine learning applications.
Raspberry Pi 4: Raspberry Pi 4 In terms of artificial intelligence (AI) and machine learning, the Raspberry Pi is a versatile instrument (ML). Coupled with a compact form factor and low power requirements, its processing capabilities make it a perfect choice for smart robotics and embedded projects.
Arduino Portenta: Arduino Portenta Portenta H7 module simultaneously runs high level code along with real time tasks. Its two asymmetric cores can simultaneously run high level code such as protocol stacks, machine learning or even interpreted languages like MicroPython or Javascript along with low-level real time tasks. PH7's main processor is a dual core unit made of a Cortex® M7 running at 480MHz and a Cortex® M4 running at 240MHz. Two cores communicate via remote procedure call mechanism that allows calling functions on other processor seamlessly.
Beagle Bone AI: Beagle Bone AI is one of the quickest vehicles to embedded AI at the edge. This super flexible and fast AI is the end product of multiple years’ research in open hardware single-board Linux computers. You can use it to automate your shop floor, home, office, or lab. The Beagle Bone AI draws its strength from the 1.5GHz, dual-core Cortex-A15 Texas Instruments Sitara AM5729 and embedded-vision-engine (EVE) neural processing cores with the AI capabilities of the SoC.
Newark has built a unique Artificial Intelligence hub with the best selection of the latest development platforms and modules, open-source projects, application kits and much more to help design engineers, makers, researchers and students to build their own AI applications or scale their current projects. For more AI and Machine learning related resources and solutions, click here
Stay informed
Keep up to date on the latest information and exclusive offers!
Subscribe now
Thanks for subscribing
Well done! You are now part of an elite group who receive the latest info on products, technologies and applications straight to your inbox.

Unleashing the AI revolution
The eBook a step-by-step guide to integrating AI technologies

Raspberry Pi solutions kits
Master the power of AI with Raspberry Pi for your personal and professional AI projects!

Step into the future!
Transforming your visions into reality with emerging technologies
Related Articles
- Advanced ML for MEMS Sensors: Enhancing the Accuracy, Performance, and Power consumption
- How to design a MEMS Vibration Sensor for predictive maintenance
- Precision in Sight: How AI-powered visual inspection improves industrial quality control
- How to Capture High-Quality, Undistorted Images for Industrial Machine Vision
- Robotics and AI Integration: Transforming Industrial Automation
- The modern challenges of facial recognition
- Intelligent cameras for smart security and elevated surveillance
- Evolution of voice, speech, and sound recognition
- AI and IoT: The future of intelligent transportation systems
- Machine Vision Sensors: How Machines View the World
- Demystifying AI and ML with embedded devices
- How to implement convolutional neural network on STM32 and Arduino
- How to do image classification using ADI MAX78000
- The Benefits of Using Sensors and AI in HVAC Systems
- Deep learning and neural networks
- Latest Trends in Artificial Intelligence
- Hello world for Machine Learning
- How to implement AR in process control application














